前回までは人工知能の一般論が中心でした。今回は、人工知能の認識精度を上げる為に、デモの開発中に試したことを説明します。
デモの内部構造について
デモの内部構造は、以下のようになっています。
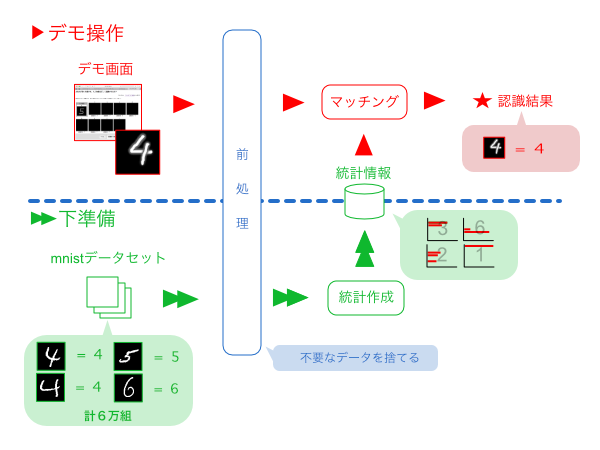
左下のmnistデータセットは、様々な人が書いた手書き数字(28×28ピクセルの白黒画像)を約6万枚集めた、一般公開されているデータ集です。それぞれの画像に、正解(0〜9のいずれか)がタグ付けされているところがポイントです。
それ以外の要素については、前回説明ずみなので説明を省きます。
検証1:前処理を工夫して、認識精度を上げる
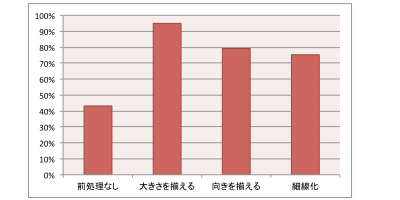
いろいろな前処理を試して、精度向上の効果を検証しました。以下は、その結果と前処理の概要です。
検証結果
 前処理なし
前処理なし
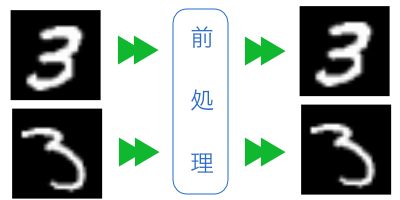
mnistデータセットをそのまま使用します。他の方法と比較するためのベースラインです。
大きさを揃える
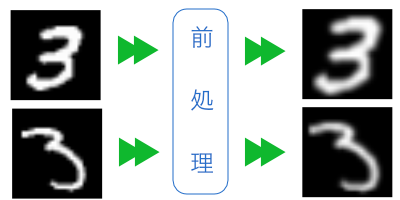
数字を認識するうえで、文字の大きさは関係ありません。ということは、大きさは認識に不要な情報と考えら
れるので、全ての手書き数字を同じ大きさに揃えて、統計に反映されないようにします。
向きを揃える
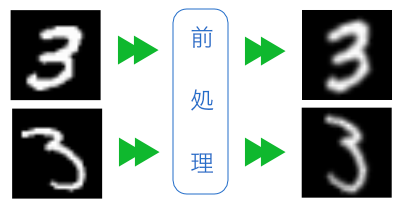
数字を認識するうえで、文字の傾き具合は関係ありません。字の向きを揃えて、統計に反映されないようにします。
細線化
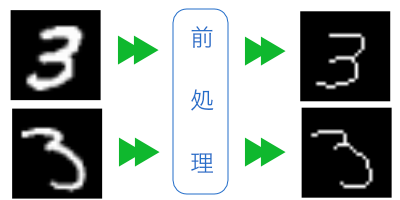
数字を認識するうえで、線の幅は関係ありません。幅を一定(1ピクセル幅)に揃えて、統計に反映されないようにします。
検証2:最適なデータ量を求める
mnistデータセットには6万の手書き数字がありますが、認識精度を上げるために、そんなに沢山のデータが必要なのでしょうか?この素朴な疑問を検証しました。
検証結果
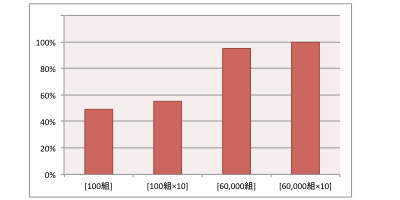
100組
mnistデータセットから、0-9の数字それぞれにつき10組を無作為抽出しました。
100組×10
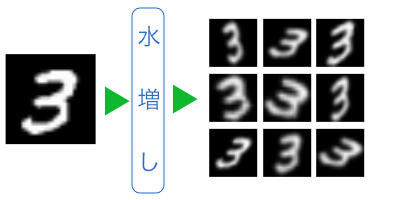
[100組]のデータセットを元に、それぞれの画像をランダムに歪めながら、10倍に水増ししました。
60,000組
mnistデータセットをそのまま使用します。
60,000組×10
[60,000組]のデータセットを元に、それぞれの画像をランダムに歪めながら、10倍に水増ししました。
検証3:デモと同じ環境を使ってデータセットを用意する
mnistデータセットの手書き数字は、ペン(もしくは鉛筆)で書かれたように見えます。一方、デモ画面ではマウス(スマホであれば指)を使って書きます。この違いが認識精度に影響するか検証しました。
検証結果
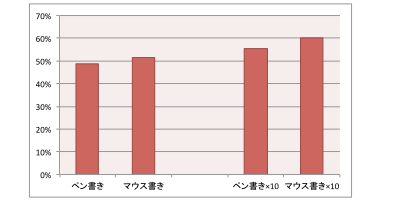
ペン書き
mnistデータセットから、0-9の数字それぞれにつき10組を無作為抽出しました。
マウス書き
デモ画面を使ってひたすらカキカキした画像を、0-9の数字それぞれにつき10枚集めました。
ペン書き×10
[ペン書き]のデータセットを元に、それぞれの画像をランダムに歪めながら、10倍に水増ししました。
マウス書き×10
[マウス書き]のデータセットを元に、それぞれの画像をランダムに歪めながら、10倍に水増ししました。
検証して分かったこと
検証1〜3のいずれについても、認識精度に影響を与える結果となりました。特に、データセット量の違いによるインパクトがとても大きいです。
個人的には、「向きを揃える」や「細線化」の前処理で精度が上がらなかったのが予想外でした。
次回(最終回)は、この結果を分析しつつ、人工知能の開発の特殊性にも触れて、本連載を締めたいと思います。
「あなたが書いた数字を、人工知能は正しく認識できるか? – 第3回(全4回)」への2件のフィードバック
コメントは受け付けていません。