人工知能が画像を認識する方法
手書き数字の画像や、音声、小説、ツィートなど、コンピューターに理解させることを前提としていない情報をコンピューターに与えて、人間のような認識をさせたい場合、大別して2種類の実現方法があります。
1. 不要なデータを捨てる
これらの入力は、一部の情報が欠落しても認識結果に影響を及ぼしません。例えば、下図の中央の画像は、左の画像の4分の1の情報量しかありませんが、人間にはどちらも問題なく認識できます。左の画像の全ピクセルが、数字の認識に欠かせない訳ではないのです。
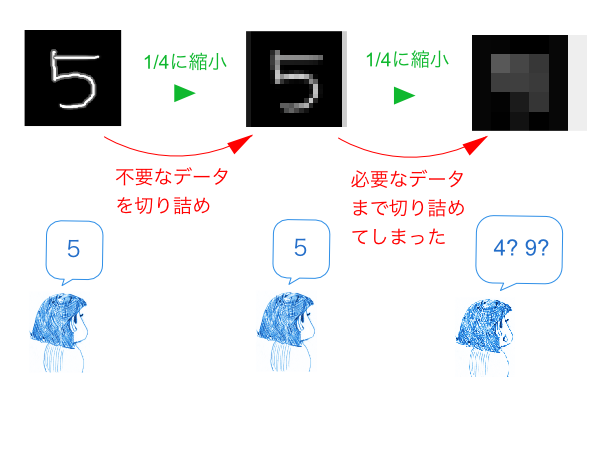
入力データから不要な情報を極限まで取り除くと、認識に欠かせない僅かなデータだけが残ります。(画像の縮小はほんの一例で、他にも様々なやり方があります)データ量が少なくなる事で、取り得るパターン数も劇的に少なくなる為、コンピューターが認識しやすくなるのです。
とはいえ、切り詰めすぎると、図の右端の画像のように必要な情報まで失ってしまい、認識できなくなります。このさじ加減は、解こうとしている問題の種類や入力データの形式などによって異なります。
2. 様々なデータを収集して「統計」を作る
28×28ピクセルの白黒画像を例にとると、ピクセル列の取りうるパターン数は”2の784乗”という途方もない数になります。しかしながら、もし仮に、世界中の人々から同じサイズの手書き数字を収集できたなら、ほとんどのパターンには該当する人がひとりもいないと予想できます。収集データの統計を取ると、以下の図のようになる筈です。
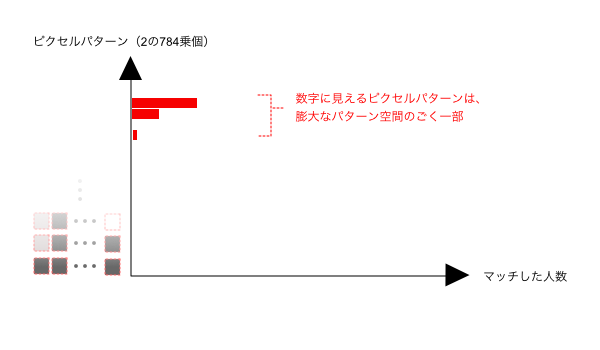
数字を書く人は誰でも、子供の頃に覚えたアラビア数字の字体をイメージしているので、これは当然の結果です。そして、この分布のバラつきは、数字を認識する上で大変役に立ちます。
”字体”の概念など知る由もないコンピューターであっても、様々な手書き数字を事前に収集して統計を作成しておけば、入力画像と統計のマッチングにより、その入力画像がなんの数字を表しているか判別できるようになるのです。
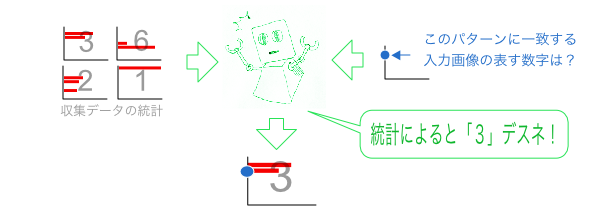
ここでは分かりやすさを優先して、縦横2軸で表現できるシンプルな統計で例えました。実際のAIは、これよりもっと多種多様で複雑な統計を使用していますが、認識方法の本質に変わりはありません。
人工知能のシステム構造
実用的な人工知能は、大抵、1と2の両方を組み合わせて使っています。素の入力データから不要な情報を取り除いた後で、統計を作成するのです。こうすると、どちらか一方を用いるよりも高い精度で分類できます。
本記事のデモも同じアプローチを採用しています。いろいろな処理方式を試して、その認識精度を評価しました。次回は、その評価結果について説明したいと思います。
「あなたが書いた数字を、人工知能は正しく認識できるか? – 第2回(全4回)」への2件のフィードバック
コメントは受け付けていません。