前回の結果から浮かび上がってきた、人工知能の特性に関する私見です。
人工知能の特性1: ヒトが見逃がす特徴を捉えられる
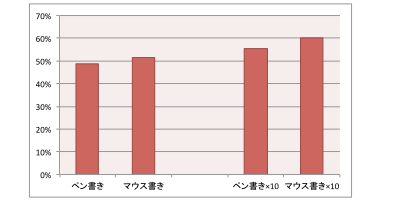
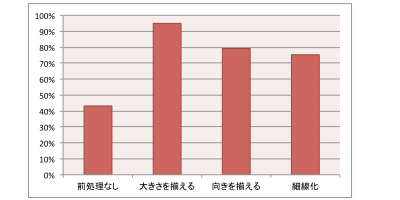
「大きさを揃える」という前処理が最も効果的でした。私は、「向きを揃える」や「細線化」のほうが、踏み込んだ処理をしている分いい結果になると予想していたのですが、意外でした。
前処理を設計した私の目論見が間違っていたと考えられます。例えば、字の傾きは、0-9の数字を見分けるのに有用な情報だったのかもしれません。「向きを揃える」ことでその手がかりを捨ててしまっていたのであれば、認識精度が下がるのも当然と言えます。
「もっと人工知能を信じて、持っている情報を全て渡しなさい!」と言われた気分です。できる部下と、その部下を過小評価しているダメ上司の関係ですね。
人工知能の特性2:新人にもベテランにもなる
前回の検証で、データセットの量が認識精度に大きな影響を与えていることが分かりました。これは、本質的に新人とベテランの違いです。
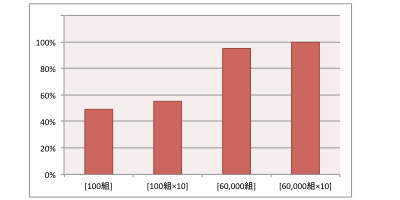
例えば、60,000組(ベテラン)と100組(新人)の人工知能について考えます。あるデモで両者が同じ認識結果を出した場合、両者の違いは分かりません。しかし、何度もデモを繰り返すと、60,000組は常に安定した認識率を維持できるのに対して、100組の方は認識率に浮き沈みが出てきます。いわゆる経験の差です。
人工知能の分野では、GoogleやFacebookなどの「データホルダー」企業が、人工知能の活用に有利と言われています。大量データを使って、人工知能をベテランに育てられるからです。
人工知能の特性3:機転が利かない
十分な量のデータセットを与えた人工知能は、頼れるベテランとして活躍してくれます。しかし、人間と違ってイレギュラーな状況で「機転」を利かせてはくれません。人工知能にデータセットのどれとも似ていない入力が与えられると、急に新人並みに頼りなくなってしまいます。
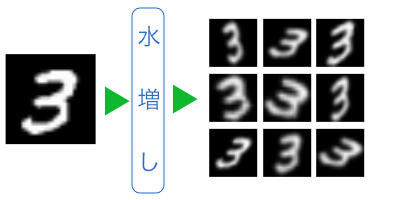
前回の、前処理を比較した結果は「前処理なし:43%」に対して「大きさを揃える:95%」と、認識率に倍以上の開きがありました。これは、mnistデータセットと似ていないデモ入力が多い程、認識率が下がることを示しています。
mnistデータセットは、どの画像もキャンバスの中央に文字が書かれています。それに対して、デモ画面はキャンバスの中央に数字を書くことを強制していません。中央から外れた場所に書かれた数字は、mnistデータセットのどれとも似ていないため、人工知能からするとイレギュラーで、認識できません。「大きさを揃える」という前処理は、このイレギュラーを予防する効果があります。
人工知能の開発手法は、従来と真逆
本記事で、「~と思います」「~と考えられます」「~かもしれません」など、あいまいな言い方を多用していることに気づかれたでしょうか?
従来のソフトウェア開発では、エンジニアがプログラムの仕様を説明するときにあいまいな言い方をする事はありません。入力をどう変換して何を出力するのか、その全てがエンジニアの意図通りにコントロールできているからです。
一方、人工知能の開発において、変換処理はブラックボックスです。その変換処理の妥当性は、実際に動かして出力(認識結果)を見るまでわかりません。
従来のソフトウェア開発で、新人プログラマーが「実装しましたが、どう動くか分かりません」と言ったら、きっと先輩に叱られます。(誰も叱ってくれないなら職場を変える事を勧めます(笑))しかし、人工知能の開発においては、”本当に” どう動くかわからないのです。
Preferred Networksの丸山さんは、これを、「演繹的システム開発」と「帰納的システム開発」の違いと説明しています。
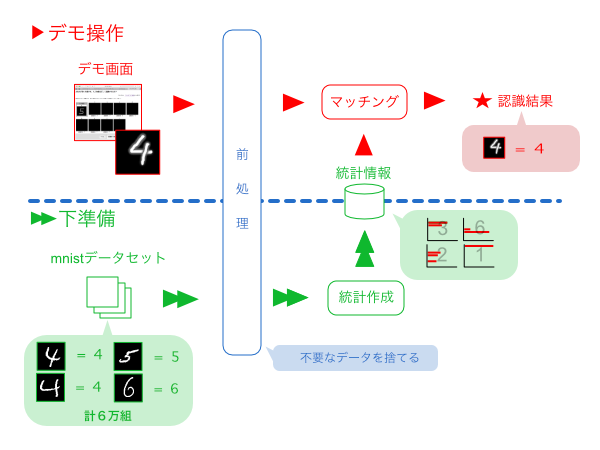
プログラムをY=f(X)と表現します。Xが入力、fが変換処理、Yが出力です。従来のソフトウェア開発は演繹的システム開発です。fをプログラマーがせっせと実装し、Xとfを与えるとYが得られます。
一方、人工知能の開発は帰納的システム開発です。本連載で”データセット”と呼んでいたXとYを与えると、fが得られます。従来は手作業で作成していたfが、人手を介さずに自動生成されます。
本連載で述べている通り、自動生成されたfの本質は「統計」です。
まとめ
「人工知能」は大袈裟に捉えられがちですが、実際にやっていることは統計データの作成と活用です。統計の価値は収集データの量と精度で決まります。それと同様に、人工知能を実用レベルに押し上げる為には、データセットの量と質がとても大切です。
そして、「動かしてみないとわからない」危うさを持っているものの、コンピューターの活躍の場を大いに広げてくれる、社会に役立つ技術です。
今の人工知能の盛り上がりは、一過性のブームで終わることなく、将来のプログラマーにとって当たり前の必修スキルになっていくと思います。
本連載を通じて、人工知能のカラクリについて理解を深めていただければ幸いです。
 前処理なし
前処理なし